

Company Description: What services did they need?
Our client, a leading player in the technology industry, embarked on the ambitious project, aiming to transcribe and analyze multilingual data transcription on a massive scale. They required a reliable partner, an LSP that specialises, with expertise in handling transcription, annotation and segmentation services for a vast array of languages. 140+ languages, out of which 110 consisted of rare languages transcription, barely spoken and written.
This project demands an LSP to effectively navigate the complexities inherent in working with diverse and challenging linguistic datasets, and tools of comprehensive transcription services. We continue to successfully master the art of efficiently using LOFT 1.0 and LOFT 2.0, powered by the groundbreaking Lamda model, to assist our client.
Services Requirements: How did we help?
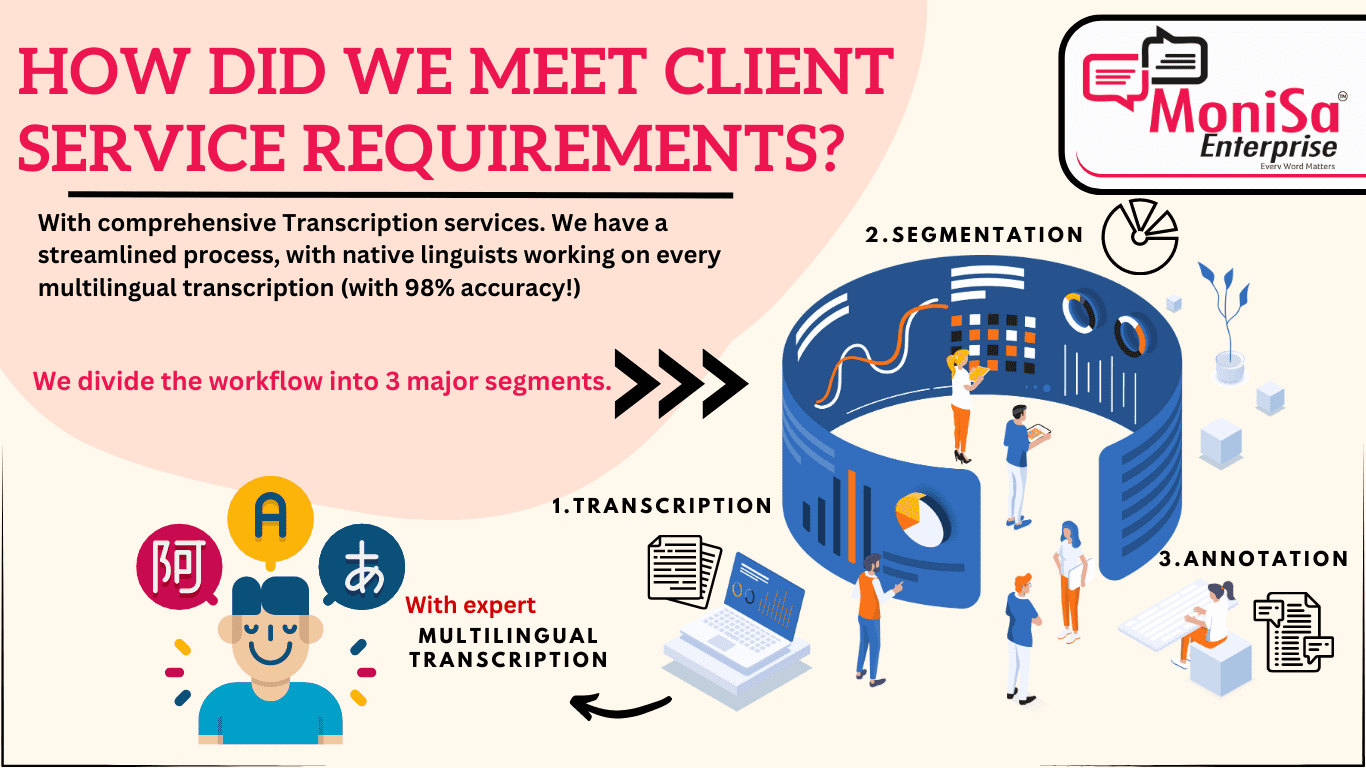
Comprehensive Transcription Services: Labelling & Annotation
In our transcription and annotation services, we ensured consistent labelling of all elements within the audio data. Our team carefully absorbed specific guidelines to avoid common errors. For instance;
- when encountering continuous noise and music throughout the audio, apply a single label to eliminate multiple labels.
- we accurately annotated every distinct typing, breathing, bird’s chirp, wind blowing, etc.
- Refrained from using “unknown” labels, and
- followed precise guidelines for labelling music and singing segments.
The project’s quality depends on enhanced annotation, these are only a few, and the most integral guidelines. Professionals with impressive knowledge of the rarest knowledge worked hours to ensure precision.
Annotation and Segmentation Services:
Our professionals first transcribed, and then annotated, adding valuable metadata and contextual information. This approach included categorization, allowing for further analysis and insights. We also paid particular attention to speaker labelling, since it’s quite tricky to maintain the order of speakers in any audio file.
Multilingual Data Transcription:
We used the revolutionary tools, LOFT 1.0 and LOFT 2.0, integrated with the advanced Lamda model, for comprehensive transcription services. Our extremely skilled linguists spent hours transcribing audio and text data, capturing the unique linguistic nuances of each language involved in the project (considering 110 were rare). The perfectly transcribed product includes all speech segments, including songs in native and foreign languages, and the corresponding lyrics accurately.
We did not just combine human effort with LOFT, we mastered the tool with training research, an unspeakable amount of passionate effort.
Segmentation:
Understanding the importance of granular multilingual data transcription, we utilized the segmentation features offered by LOFT 1.0 and LOFT 2.0. The transcription team applied segmentation techniques for breaking down the transcribed content into meaningful units. This allows us to organise the work before refining it. Some great segmentation techniques used were;
- Ending a speaker’s turn before pauses longer than 0.5 seconds and creating new turns when speakers resumed talking.
- Segment boundaries, for accuracy with at least 100ms accuracy.
Our expertise in handling complex linguistic requirements, combined with the advanced capabilities of LOFT 1.0 and LOFT 2.0, is what made this project possible. However, we wish to share some overview of these tools, and their challenges, to highlight our efforts.
Read More – Effect of AI on Localization Now a Days
Project Overview: Combining Human Effort & LOFT Project Tools
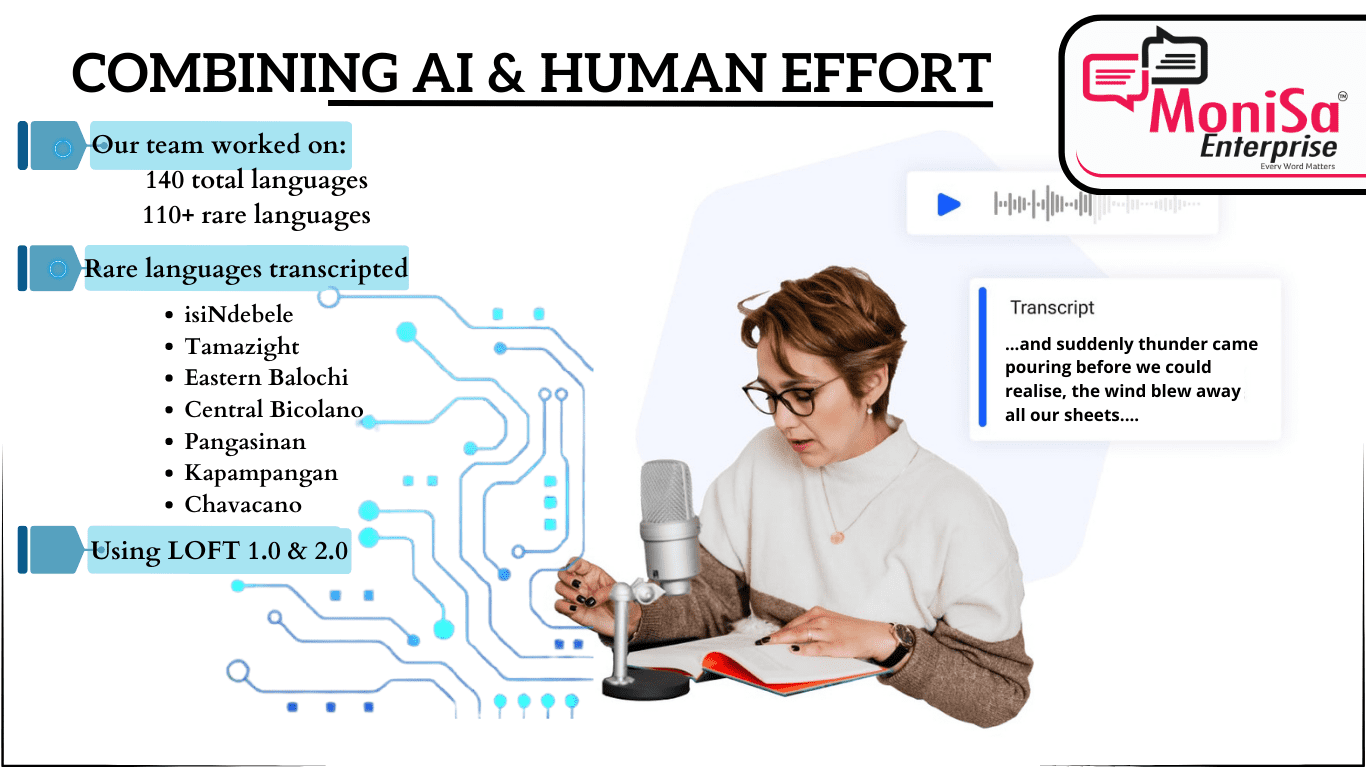
Our team at MoniSa Enterprise has successfully worked with over 140 languages, including an impressive repertoire of 110+ rare languages transcription. These rare languages have limited national recognition and are not commonly used. Here’s a list of the rarest languages we worked on;
- Nigerian Fulfulde
- isiNdebele
- Tamazight
- Eastern Balochi
- Central Bicolano
- Pangasinan
- Kapampangan
- Chavacano
- Javanese
- Hakka chin
- Nigerian fulfule
- Isoko
- Eastern balochi
- icelandic
The LOFT project tools, however, are even more interesting.
These language models were designed to overcome the limitations of traditional rule-based chatbots for more natural and contextually relevant responses. Throughout the project, we encountered various complexities inherent in developing the Lamda model and integrating it into the LOFT systems for comprehensive transcription services. Yet, our experts are too familiar with the challenges, to know the exact solution(s).
LOFT 1.0
Improving Chatbot Conversational Abilities LOFT 1.0, short for Language Online Understanding and Feedback Tool, was initially aimed at improving the capabilities of chatbots. One of the primary objectives was to develop a model that engages in dynamic conversations, understands context, and generates coherent responses.
- Reinforcement Learning from Human Feedback
LOFT 1.0 leveraged RLHF to train the language model. Operators provide initial responses to user queries, and the model learns from these interactions. - Proximal Policy Optimization (PPO)
Optimizes its performance based on feedback from both operators and users for better transcription, annotation and segmentation services. - Enhanced Conversational Abilities
LOFT 1.0 and LOFT 2.0 both address user queries more effectively.
LOFT 2.0
Advancements with the Lamda Model Building with the success of LOFT 1.0, LOFT 2.0 was introduced, incorporating the powerful Lamda model to generate more diverse and contextually relevant responses. The Lamda model showcases a significant leap in conversational AI capabilities.

Lamda/ MU Model:
It is a deep learning model designed as a conversational AI. It is trained on a diverse range of data, including books, articles, and websites, to develop a comprehensive understanding of language, multilingual data transcription and context. Our experts can train it just right for annotation and segmentation services, comprehensive transcription services, and labelling. It has a transformer architecture to understand complex relationships and dependencies in text data, resulting in more coherent responses and free-flowing conversations, understanding nuanced prompts, and providing more personalized responses.
Complexities in the Lamda Model Development, LOFT 1.0 and LOFT 2.0

1. Training on Diverse Data:
Incorporating a wide range of data sources posed challenges in terms of multilingual data transcription collection, preprocessing, and training. The team had to carefully curate and sanitize the training data to ensure the model learned from a diverse and representative set of sources.
2. Ethical Considerations:
Training the Lamda model required extensive efforts to mitigate biases, offensive content, and misinformation.
3. Context Understanding:
Teaching the Lamda model to understand and generate contextually appropriate responses was a complex task, that we eventually we overcame.
Efficient Workflow Management
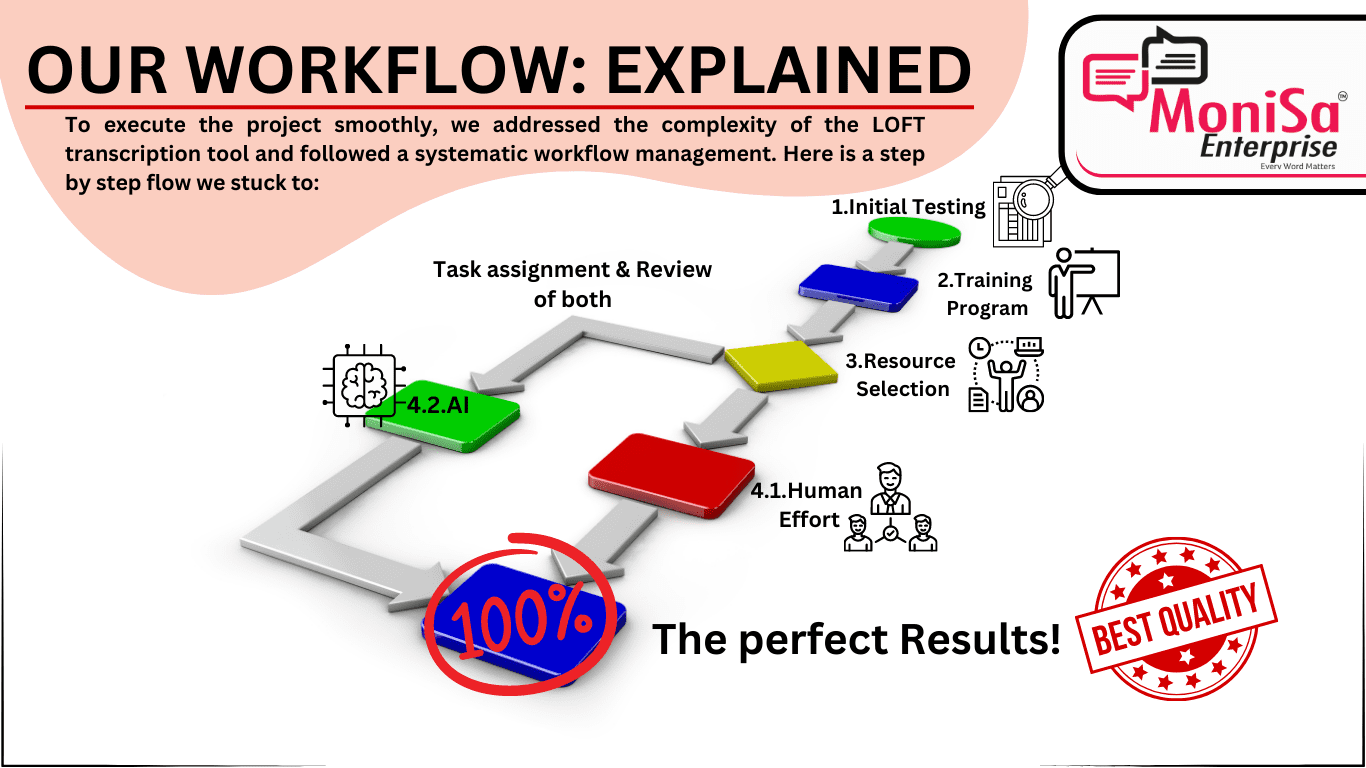
To ensure smooth project execution, we addressed the complexity of the LOFT transcription tool and the need to onboard transcribers, many of whom were unfamiliar with the tool. Our process involved the following steps:
- Resource Selection:
We hired a diverse pool of resources proficient in both general and rare languages transcription pairs. - Initial Testing:
Candidates underwent a rigorous testing process to assess their transcription skills and proficiency in using the LOFT 1.0 and LOFT 2.0. - Training Program:
Successful candidates underwent a comprehensive two-day training program to familiarize themselves with the intricacies of the LOFT tool - Task Assignment and Review:
Our operations team diligently assigned tasks to transcribers, ensuring a balance between production and quality assurance projects. Each completed task underwent thorough review and necessary corrections by our expert review team before final submission.
Overcoming Challenges: A Solution to Resource Crisis
The primary challenge encountered during the project was identifying and training resources for the rare language pairs to achieve a high level of accuracy (95%) in comprehensive transcription services. We leveraged our extensive network and dedicated efforts to locate and train talented professionals in these rare languages transcription, ensuring they could proficiently navigate the complex LOFT 1.0 and LOFT 2.0 tools.
Read More – Embracing Excellence In Translation – CITLoB Membership, Assurance Of Quality Services
Impressive Output:
Since commencing the LOFT project in March 2020, we have made remarkable progress, having worked on over 140 languages, delivering over 8,000 hours of production work, and 2,500 hours of quality assurance tasks. Our team’s commitment to accuracy, efficiency, and quality has consistently exceeded the client’s expectations.
Solving Customer Problems:

Our partnership with the client has alleviated their concerns regarding finding experienced teams proficient in using LOFT 1.0 and LOFT 2.0. We have successfully provided high-quality output from each resource involved in the project, eliminating the need for the client to search for multiple language-specific solutions. Our ongoing collaboration allows the client to rely on us as a comprehensive, one-stop solution for all their language requirements throughout the project’s lifecycle. With continuous expansion, we continue to add more languages and resources, ensuring scalability and superior service.
Read More – Corporate Transcription Benefits
Simplifying LOFT Projects with MoniSa Enterprise
Through our dedication, expertise, and meticulous approach, MoniSa Enterprise has played a pivotal role in supporting the LOFT project for extensive multilingual data transcription, annotation and segmentation services. Our ability to handle a wide range of languages, including rare and complex transcription tasks, has provided the client with unmatched value and peace of mind. We remain committed to delivering exceptional results, exceeding expectations, and supporting our clients in achieving their language-related objectives.
Project Review
- Used native speakers and licensed professionals to maintain superior results using LOFT 1.0 and LOFT 2.0.
- Real-time feedback process allowed 100% customer satisfaction with no extension in deadline.
- Compliance with LOFT guidelines has driven better opportunities in comprehensive transcription services, even for rare languages transcription.
